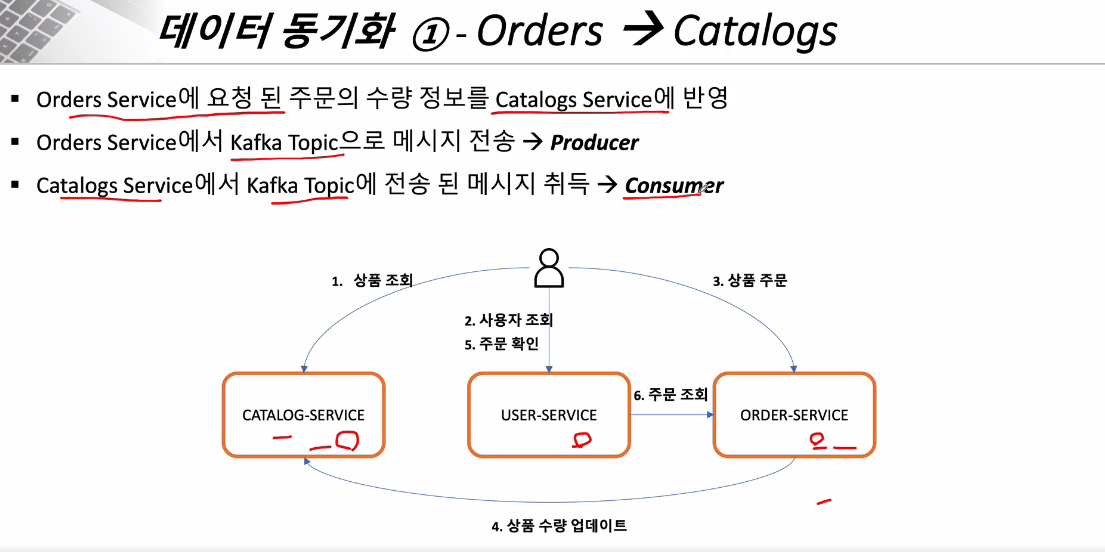
RestTemplate나 FeignClient 통하여 MicroService간 통신함.
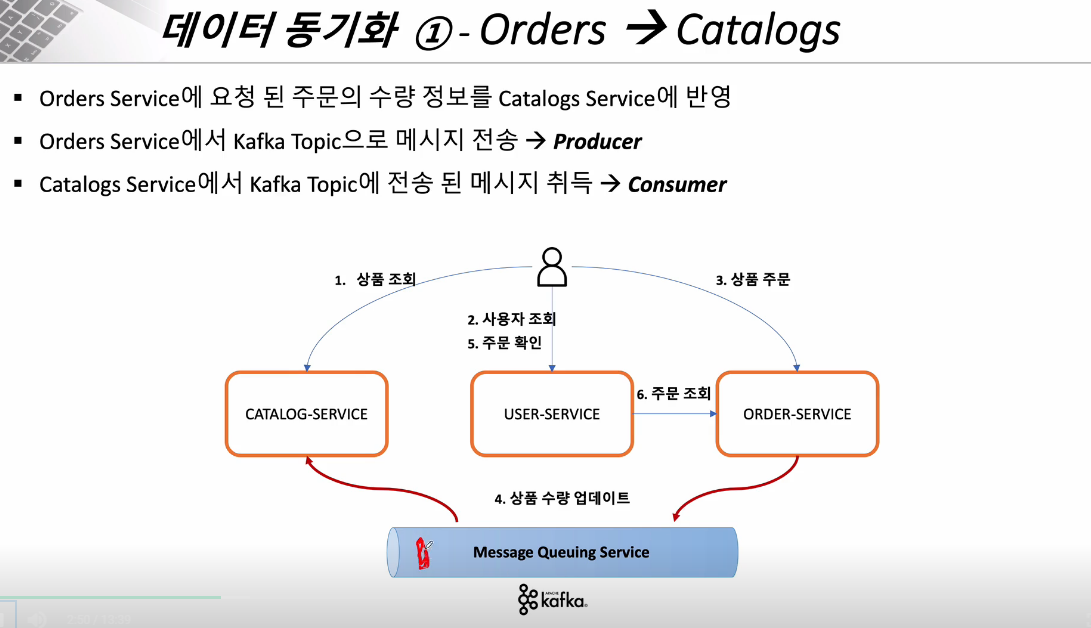
Kafka 통하여 통신함 (Producer/Consumer)

Kafka Topic & Listener 이용하는 방법. (그런데 이건 서비스 여러개 켰을 때, 토픽 1개 저장했을 때 하나의 서비스에서만 db에 업데이트 되는 것 확인하였음.. 하나의 서비스의 토픽 listener가 consume하고 사라져서 그런가..)
아래와 같은 listener를 만들어놓으면, 본인이 구독하는 topic 정보가 업데이트 되면 listener가 알아서 실행되는 방법
아래와 같은 DTO 객체를 직렬화해서 topic 이름 붙여서 kafka 클러스터로 보내면, consumer에서는 해당 topic이름으로 보내진 data를 읽어서 사용 가능하다.
{
"productId": "CATALOG-002",
"qty": 30,
"unitPrice": 1500,
"totalPrice": 45000,
"orderId": "c49d3db8-f907-40a4-9142-8fa78c0265f6",
"userId": "fdccff6d-9be2-446c-85c8-e5791276b183"
}
@Service
@Slf4j
public class KafkaProducer {
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate){
this.kafkaTemplate = kafkaTemplate;
}
public OrderDto send(String topic, OrderDto orderDto){
ObjectMapper mapper = new ObjectMapper();
String jsonInString = "";
try{
jsonInString = mapper.writeValueAsString(orderDto);
}catch (JsonProcessingException ex){
ex.printStackTrace();
}
kafkaTemplate.send(topic, jsonInString);
log.info("Kafka Producer sent data from the Order microservice : " + orderDto);
return orderDto;
}
}@Service
@Slf4j
public class KafkaConsumer {
CatalogRepository repository;
@Autowired
public KafkaConsumer(CatalogRepository repository) {
this.repository = repository;
}
// 이 토픽에 데이터가 전달이 되면 그 데이터 값을 가져와서 이 메서드가 실행이 된다.
@KafkaListener(topics = "example-catalog-topic")
public void update(String kafkaMessage){
log.info("Kafka Message: -> " + kafkaMessage);
Map<Object, Object> map = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
try{
map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {});
}catch (JsonProcessingException ex){
ex.printStackTrace();
}
CatalogEntity entity = repository.findByProductId((String)map.get("productId"));
if(entity!=null){
entity.setStock(entity.getStock() - (Integer)map.get("qty"));
repository.save(entity);
}
}
}
Kafka Connect
현재까지 파악된 바로는 kafka connect를 사용해서 동기화 하는 방법으로는 아래 2가지가 있음.
1. 특정 Table에 Source Connect 걸었을 때, 그 Table에 변경사항 생기면 event가 발생하는 것 처럼 아래와 같은 json파일이 자동으로 생성되어 해당 Topic으로 저장됨.
그러면 Sink Connect 걸린 DB에서 해당되는 테이블에 정보를 자동으로 업데이트 진행함.
2. 특정 table에 source Connect 거는 것이 아니라, 특정 api 호출 시 아래와같은 json 스키마를 생성하여 바로 kafka connect 서버로 전송하여 topic 저장함. 그러면 sink connect 걸린 db가 자신의 topic이라면 data를 찾아가서 업데이트 하는 방식
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"field": "order_id"
},
{
"type": "string",
"optional": true,
"field": "user_id"
},
{
"type": "string",
"optional": true,
"field": "product_id"
},
{
"type": "int32",
"optional": true,
"field": "qty"
},
{
"type": "int32",
"optional": true,
"field": "unit_price"
},
{
"type": "int32",
"optional": true,
"field": "total_price"
}
],
"optional": false,
"name": "orders"
},
"payload": {
"order_id": "1736abdd-1f95-4457-9341-1943100fcc60",
"user_id": "fdccff6d-9be2-446c-85c8-e5791276b183",
"product_id": "CATALOG-002",
"qty": 30,
"unit_price": 1500,
"total_price": 45000
}
}
'MSA > MSA관련기술' 카테고리의 다른 글
| 서킷브레이커 (Resilience4j) 환경설정 방법 (0) | 2022.12.06 |
|---|---|
| CircuitBreaker(서킷 브레이커)와 Resilience4J (0) | 2022.12.06 |
| kafka 설치 & 환경구성 (0) | 2022.12.02 |
| Redis 환경설정 방법 (0) | 2022.11.29 |
| 서버 성능 측정 방법 (0) | 2022.11.29 |


댓글